云服务设计模式
参考:
《Cloud Design Patterns: Prescriptive Architecture Guidance for Cloud Applications》
大使模式 Ambassador
大使模式创建了一些服务帮忙代理客户服务发送业务无关的网络请求,比如路由、监控、配置更新、安全性(TLS)、鉴权等。一些遗留代码没有开发人员维护,而且不同的客户端可能使用不同语言框架编写,如果各自实现这些必须的功能,更新服务代码时就会有较大的风险。
这些功能可以实现到一个代理服务中,作为一个 sidecar 和客户端部署在同一个实例里,用来控制路由、弹性、安全特性,它也可以监控性能指标比如延迟、资源使用率等。
考虑点
- 代理增加了一定的延迟,所以也可以考虑设计为一个库,让客户端直接调用。
- 可以考虑在代理中实现通用的特性,比如重试,但需要注意操作是否是幂等的。
- 提供一套机制可以让客户端配置代理的行为,比如重试次数、超时时间、日志级别等。可以是 HTTP 的 header 或者 query 参数。
- 考虑如何打包和部署代理服务。
- 考虑是否为所有客户端实现一个共享的代理服务还是各一个。
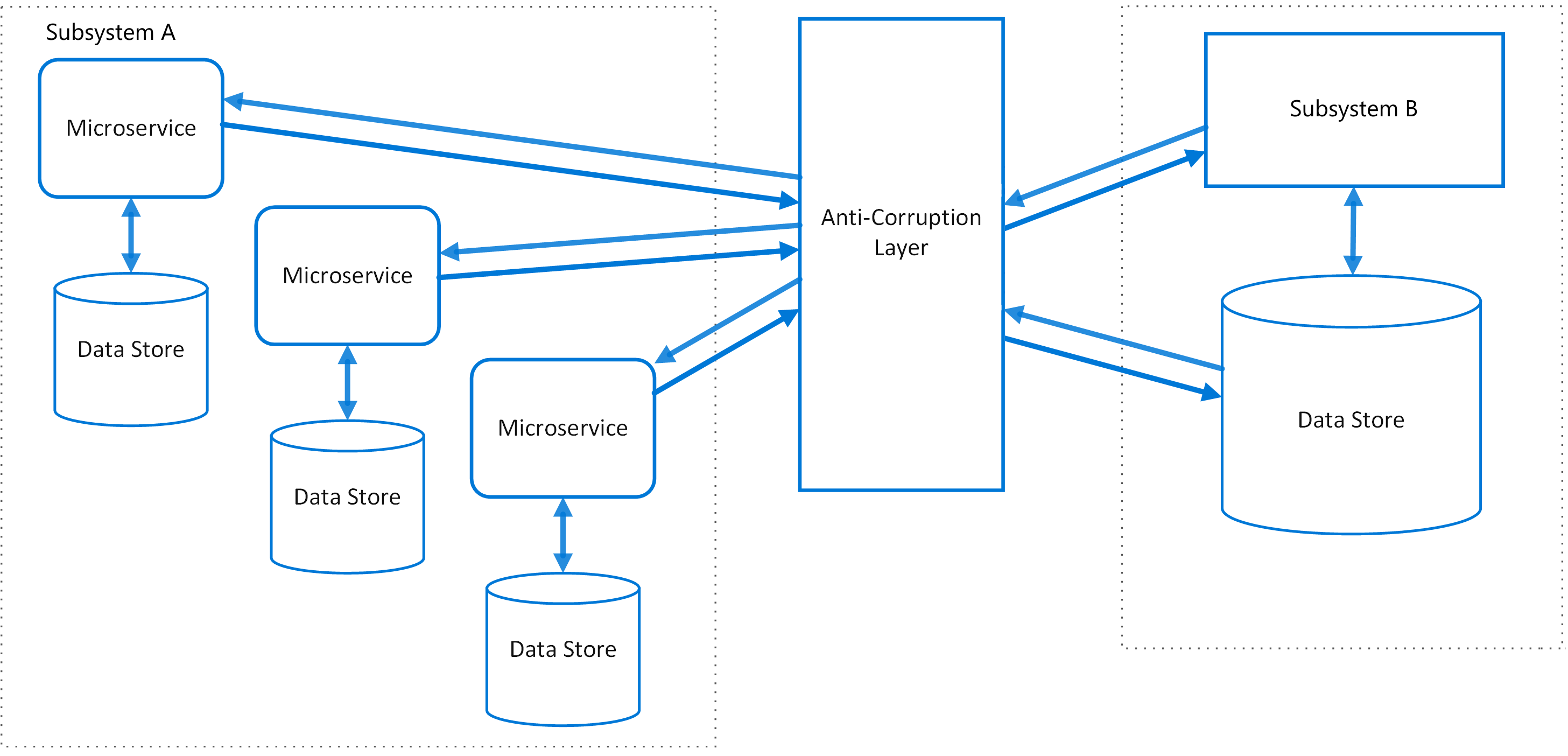
防腐层 Anti-Corruption Layer
在不共享相同语义的多个子系统之间实现门面(Facade)或适配器层。将一个子系统向另一个子系统发出的请求转换。确保应用程序不受对外部子系统的依赖关系的限制。此模式最早在 Domain-Driven Design 中提出。
在系统升级架构时,新的功能可以还依赖旧的资源,新的系统为了和旧的系统交互,还需要引入过时的基础设施、协议、数据结构、APIs等。新系统就很难保持干净的设计了。
防腐层将不同的子系统隔离开,相当于为两个系统提供了一个翻译通信的接口。
考虑点
- 防腐层可能增加延迟和额外的维护成本。
- 考虑防腐层要如何扩展。
- 考虑如何管理防腐层,协调它和其它应用的关系,如何集成到监控、发布、配置等流程中。
- 考虑防腐层是处理所有通信还是部分。
- 如果防腐层是作为系统迁移策略,可以它是长期存在还是最终会移除。
异步请求-应答 Asynchronous Request-Reply
等待请求完全处理完再返回,有时候并不实际,因为一些情况会导致请求运行很久,用户的体验会变差。有些架构下通过消息队列来隔离请求和响应的阶段,但客户端就需要拿到结果成功的通知。在微服务架构下,也可以使用 HTTP 的长轮询(polling)来实现。相比提供一个call-back 接口,这种方式更简单。
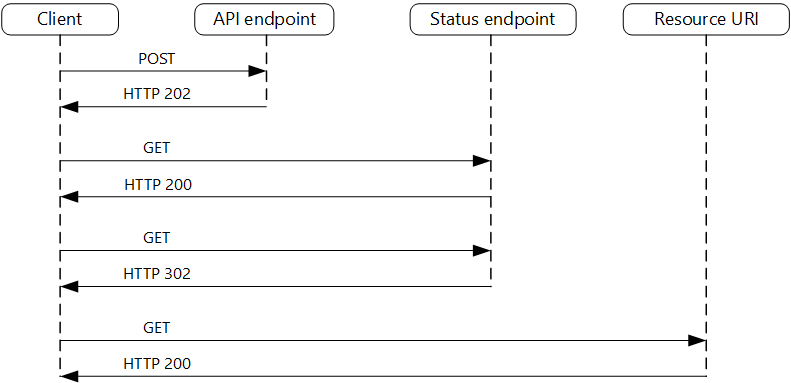
处理示例
- 客户端通过同步的调用,API 直接返回 HTTP 202 Accepted 状态码。并在 Location header 里提供一个可以查询结果的状态的 URL,在 Retry-After header 里提供预估的请求完成的耗时。
- 客户端使用 polling 的方式,每隔一段时间向服务端请求状态。
- 状态端口对于成功的调用,都返回 HTTP 200 OK 状态码。一旦处理完成,可以返回相应的资源,或者是提供获取资源的 URL(并返回 HTTP 302 Found/303 See other 状态码)。
- 客户端读取资源,对应资源的端口应该返回 HTTP 200 OK 或 201 Created 或 204 No content。
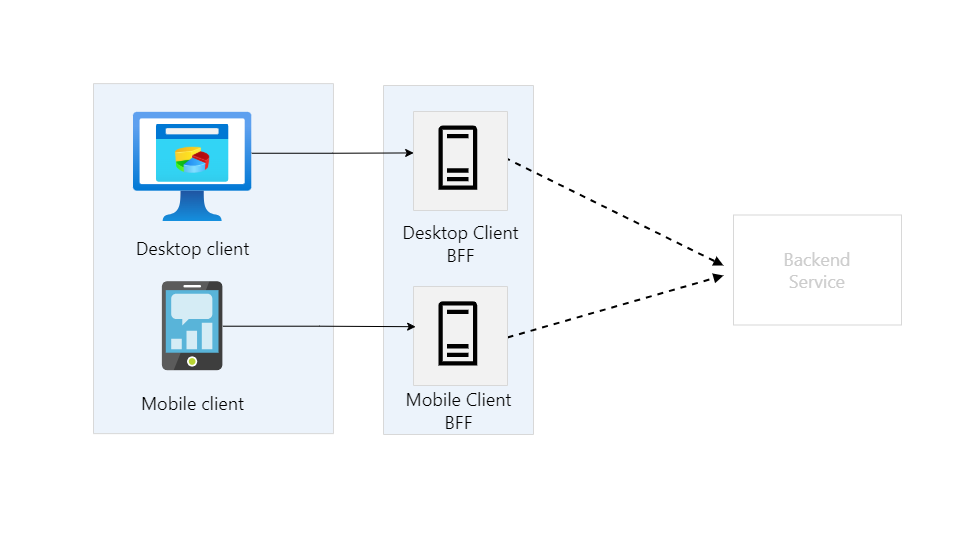
为前端提供后端 Backends for Frontends (BFF)
不同前端,比如桌面端和移动端,可能对后端的需求不同,为了保持兼容性和处理差异,维护单一的后端的工作量会很大。因此可以增加一层,称为 BFF,它针对不同的前端,提供不同的后端服务。
考虑点
- BFF 是一个独立的服务,也意味着增加了维护成本。所以要权衡考虑。
- 需要考虑 Service Level Objectives (SLOs) 和 Service Level Agreements (SLAs),因为增加了一层,也会增加请求延迟。
- 需要权衡构建新的后端的代价和维护现有后端的技术债。
- 如果已经使用了 GraphQL,前端可以灵活获取所需数据了,那么 BFF 就没有必要了。
舱壁 Bulkhead
舱壁是一种典型的容忍错误的系统设计,隔离系统的不同部分,防止一个部分的故障影响到其它部分。这个命名来自船体的分段隔板,船体部分受损,就只有受损部分进水,防止船沉没。
每个云服务有多个用户,如果其中一个用户使用超额的资源,或者产生了错误,就容易影响其它用户。
把服务拆分为不同资源组,可以隔离用户的错误。用户也可以隔离不同的服务连接池,这样一个服务请求失败不会影响它请求其它服务。
旁路缓存 Cache-aside
根据需要从数据库加载数据到缓存里,可以提升系统性能,并且维护缓存和数据库里的数据的一致性。
需要设计一个策略可以保证缓存是最新的,且能够检测并处理缓存过期的情况。
商业化缓存系统一般提供 read-through, write-through 和 write-behind 的操作。应用服务把 cache 当做主要数据源,由 cache 服务负责数据库的读写。
- read-through 读穿透
- 当缓存中没有数据时,从数据库中读取数据,并将数据写入缓存再返回。
- 当缓存中存在数据时,直接返回缓存中的数据。
- write-through 写穿透
- 当缓存中没有数据时,更新数据库。
- 当缓存中存在数据时,更新 cache,并将数据写入数据库。
- write-behind 异步缓存写入
- 只更新缓存,后面再异步批量地写入数据库。
通过实现 Cache-aside 模式可以让系统执行 read-through 的功能:
- 读:当缓存里没有数据,从数据库读取数据,并将数据写入缓存再返回。
- 写:修改数据库的数据,把缓存标记为失效。
考虑点
- 合理设置缓存数据的生命周期:太长容易拿到过期数据,太短则容易频繁读写数据库。
- 数据驱逐:缓存的空间有限,一般会采用最近最少使用的淘汰策略,但也可以根据实际情况调整,例如某个数据读取的代价较大,可以将该数据的缓存设置为永不过期。
- 启动缓存:在系统启动时,预先将数据加载到缓存中,避免冷启动时的性能问题。
- 一致性:如果数据被其它服务修改,Cache-aside 模式会导致数据不一致,可以增加过期策略。
- 本地(In-Memory)缓存:使用本地缓存不能共享数据,容易导致数据不一致。设置数据过期、更频繁地刷新数据就变得非常必要。或者使用分布式缓存。
编排 Choreography
将工作流逻辑分离出来,云服务上的一个操作,通常需要调用多个服务,理想情况下,这些服务之间应该是解耦的。但它们之间存在复杂的服务间通信。
常见的设计是一个中心化的编排服务 orchestrator,把到来的请求委派到相应服务上。编排器具有业务上下文,可以有效地处理每个下游服务的结果,合并最终结果。但编排服务会变得复杂,且可能成为单点故障,或导致下游级联故障。
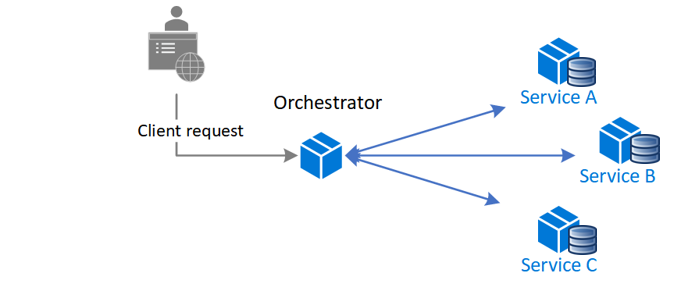
而编排的方法则是通过消息代理来实现,每个下游服务订阅消息,当消息到达时,每个服务可以片段是否需要他们处理,需要则处理后将结果返回到同个信息队列或新的信息队列,再由其它服务片段是否需要处理。
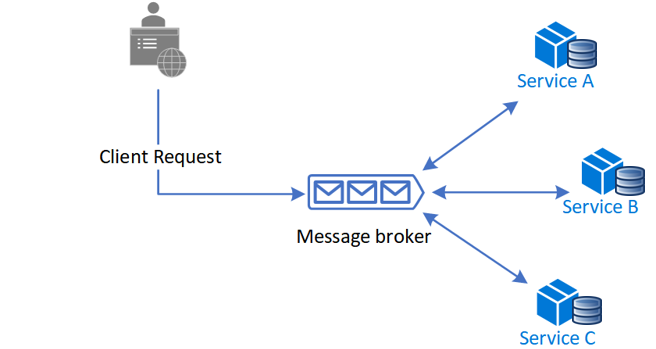
考虑点
- 当产生错误时,可能需要使用补偿事务,可能会让系统变得更加复杂。
- 工作流相对简单,以及组件频繁更新(新增、删除)时,适合使用这种模式,减少了对现有服务的改动。
熔断器 Circuit Breaker
系统因为瞬时错误比如网络慢导致的失败,可以通过重试来解决。但是一些更难以自动恢复的错误,使用重试就没有用了。服务繁忙时,一部分系统的错误可能导致级联故障,导致整个系统瘫痪。需要合理设置超时时间,超时太长会导致长时间占用资源。
熔断器在判断出系统错误无法快速恢复时,阻止当前请求,通过特定错误告诉重试机制停止重试,让当前请求立即失败。它用于在系统中保护关键组件,避免因依赖的服务不可用或响应缓慢而导致整个系统崩溃。
熔断器状态
熔断器有三种状态:
- Closed 关闭:熔断器关闭,允许请求通过。
- Open 打开:熔断器打开,拒绝所有请求。
- Half-Open 半开:熔断器打开一段时间后,进入半开状态,允许部分请求通过。
状态切换:
- 熔断器关闭时,如果请求失败次数超过阈值,熔断器切换到打开状态。
- 熔断器打开时,如果请求成功次数超过阈值,熔断器切换到关闭状态。如果定时器超时,熔断器切换到半开状态。
- 熔断器半开时,如果请求成功次数超过阈值,熔断器切换到关闭状态。如果请求失败次数超过阈值,熔断器切换到打开状态。
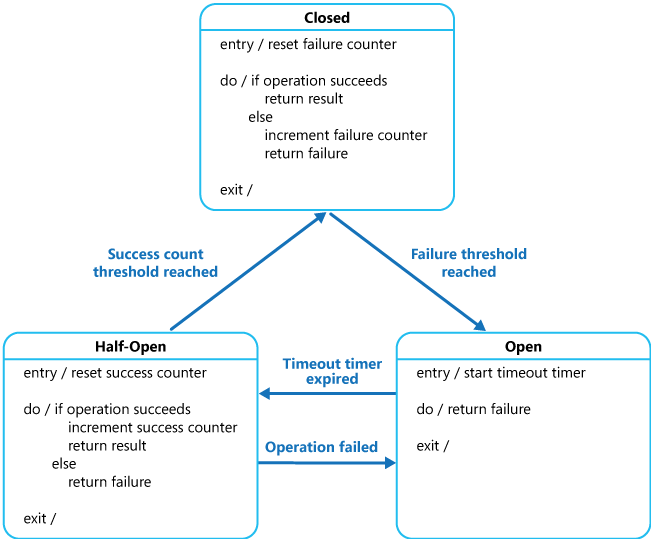
考虑点
- 定制定时器:可以设置不断增加的定时器,适应不同故障情况。但定时器也不能太长,否则可能问题以解决但还在拒绝请求。
- 错误类型:对不同的错误类型设置不同的阈值。
- 测试失败服务:除了通过定时器超时来改变状态,也可以通过定时测试失败的服务来观察是否恢复,例如请求失败服务的健康端口。
- 手动切换:某些情况,管理员可以强制关闭或打开熔断器会非常有用。
- 并发:需要考虑到熔断器被并发使用的情况,不应该阻塞请求或增加额外负担。
- 资源差异:如果有不同的资源,应当使用不同的熔断器,否则有可能阻断可以成功的请求。
补偿事务 Compensating Transaction
如果一个或者多个操作失败,需要回滚之前的操作,确保数据的一致性。
云应用程序使用分布式的存储,为了提高性能,往往不保证事务一致性,而是使用最终一致性。而最终一致性的挑战是如何处理已不可恢复的失败的步骤。这种情况需要撤销前面的步骤。如果操作本身跨越多个服务,使用不同的数据存储,就必须通过补偿事务来实现。
在面向服务的架构 Service Oriented Architecture (SOA)中,之前的操作可能修改了服务状态,则需要通过调用服务的另一个方法来撤销之前操作的影响。
通常的实现是执行一个工作流,在原始操作执行时,系统记录每一步的信息,及如何撤销。当错误发生时,系统逆向执行工作流,撤销之前的操作。并且可以并行执行撤销的工作流。
补偿事务本身也是最终一致性的操作。系统有可能在执行时发生故障,因此会需要恢复继续执行工作流,因此这些操作应当是幂等的。
竞争消费者 Competing Consumers
多个并发的消费者从同一个消息队列中读取消息,均衡工作负载。
计算资源合并 Compute Resource Consolidation
整合多个任务为一个计算单元,提升资源利用率,减少资源浪费。
命令与查询责任分离 Command and Query Responsibility Segregation (CQRS)
将读取和写入分离,提高系统的可扩展性、性能和安全性。
事件溯源 Event Sourcing
记录某个领域下数据的所有动作事件,而不只是记录数据的最终状态。降低了同步数据的复杂性。
外部配置存储 External Configuration Store
方便管理、共享配置。
联合身份 Federated Identity
使用外部身份提供商进行身份验证和授权。优化用户体验。
门卫 Gatekeeper
使用特定的主机实例作为中间人来验证、清理请求。保护系统的安全性。
健康端点监控 Health Endpoint Monitoring
通过暴露端口,可以利用外部监控工具定期查询系统的状态。
索引表 Index Table
对于常用查询的字段,建立索引表,提高查询性能。
领导者选举 Leader Election
多个任务实例中,选出一个作为领导者,负责管理其他任务实例。
物化视图 Materialized View
当数据字段的格式不利于查询操作时,生成预计算的视图查询结果,提高查询效率。
管道与过滤器 Pipes and Filters
分解复杂任务为离散的可被复用的子任务,提高系统的可维护性和可扩展性。
优先队列 Priority Queue
让更高优先级的任务可以更快地被处理。
队列负载均衡 Queue-based Load Leveling
在请求和服务之间使用队列作为缓冲,以平稳间歇性的峰值负载,否则这些负载可能导致服务失败或任务超时。
重试 Retry
运行时重新配置 Runtime Reconfiguration
在运行时修改配置,而不需要重启应用程序。
调度器代理监督者 Scheduler Agent Supervisor
处理故障或撤销已执行工作的影响。恢复并重试因瞬时异常、持久故障和进程故障而失败的操作,来增强分布式系统的弹性。
分片 Sharding
水平拆分数据。
静态内容托管 Static Content Hosting
将静态内容部署在云存储上,减少对昂贵的计算实例的需求。
限流 Throttling
控制单个实例、应用、用户或整个服务的资源使用量。
钥匙 Valet Key
让用户使用 token 或 key 访问受限资源。